%20(42%C2%A0%C3%97%C2%A020%C2%A0cm).png)
Share this post



After a first project on a Domain Driven Hexagon architecture, I want to share the learnings I have made to help other beginners face the elephant in the room
Recently, I realized my first mission on a Hexagonal Architecture project with a special implementation: Domain Driven Hexagon.
This approach was created by Sairyss in a Github repository (link at the bottom of the article) in 2020. It is increasingly popular, but it tends to have some trouble democratizing. Actually, it’s quite understandable because it is hard to apprehend initially (and even several months after). However, it is really powerful, and it deserves more visibility.
To give you more context, Domain Driven Hexagon is based on Hexagonal Architecture theorized by Alistair CockBurn in 2005. It deals with Domain Driven Design (DDD), introduced by Eric Evans in 2004. DDD aims to help all stakeholders to create a shared vision and lexicon in order to better apprehend its complexity. Domain Driven Hexagon also uses some concepts of Command Query Responsibility Segregation (CQRS) pattern. Which was coined by Bertrand Meyer in 1988.
Spoiler alert: this article is not supposed to give the pros and cons of DDH. It aims to be helpful for a developer who begins on a project with such an architecture. I just want to give you some small keys that I wish I had when I dove into the code.
If you get to those lines, this article is surely made for you. So let’s dive in. Here are 9 points that I hope will demystify a little some key concepts of DDH:
Info: To improve readability, this article does not contain code. If you want to see implementation examples, I created a repository (link at the end of the article). It represents some parts of a pizza restaurant with a DDH approach. Besides, all examples of the article are linked with this pizza restaurant.

A back-end divided into three parts
In DDD (Domain Driven Design), one of the first objectives is to determine bounded contexts. A bounded context is a set of things from the business that can have a unified model together. And if you add one other thing to this model, you risk having an ambiguity on a word in the vocabulary.
For example, in our pizza restaurant, something as simple as a dish has different meanings: for a customer, it is something on the menu, a receipt for the cook, and a command for the server. We may define 3 bounded contexts, one for each business in a restaurant (service, cooking, and client).
In DDH, each bounded context will be implemented as a module. In a module there are always three parts which can be represented as following:
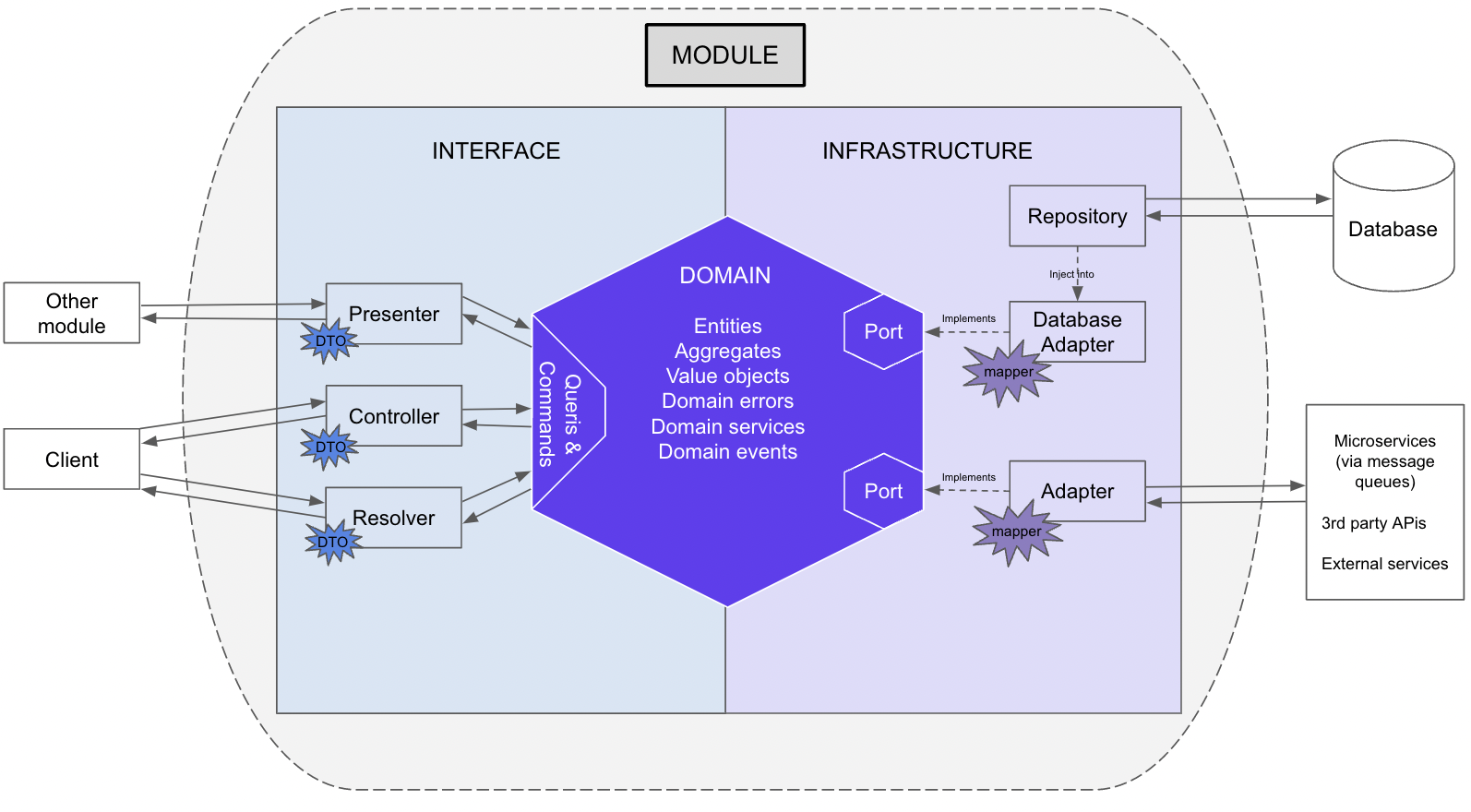
Diagram inspired by Sayriss repo. (NB: I will be consistent in the colors of every schema in this article. It means, for example, that I will use purple only for elements that should be in the domain)
Inverse dependency injection with ports and adapters
As DDH aims to respect SOLID principles, this concept is respected. The domain should be independent (from everything). It is the hexagonal architecture that will help us achieve that.
Dependency inversion principle, one of the SOLID principle.
To do it, the domain will tell with interfaces what it expects to have out of its border. Those interfaces are the ports. On the other side of the border, in the infrastructure, adapters are the classes that implement the ports. They contain the particular logic linked to the chosen external service.
A simple metaphor in our pizza restaurant is the hiring of a new delivery guy. The only question that the owner can ask the candidate is if he is able to go from the pizzeria to an address with the pizzas. If the candidate can, then the owner can hire him. It does not matter that this delivery guy goes with a bike or with a motorcycle, if he writes the address on his phone or on a GPS...
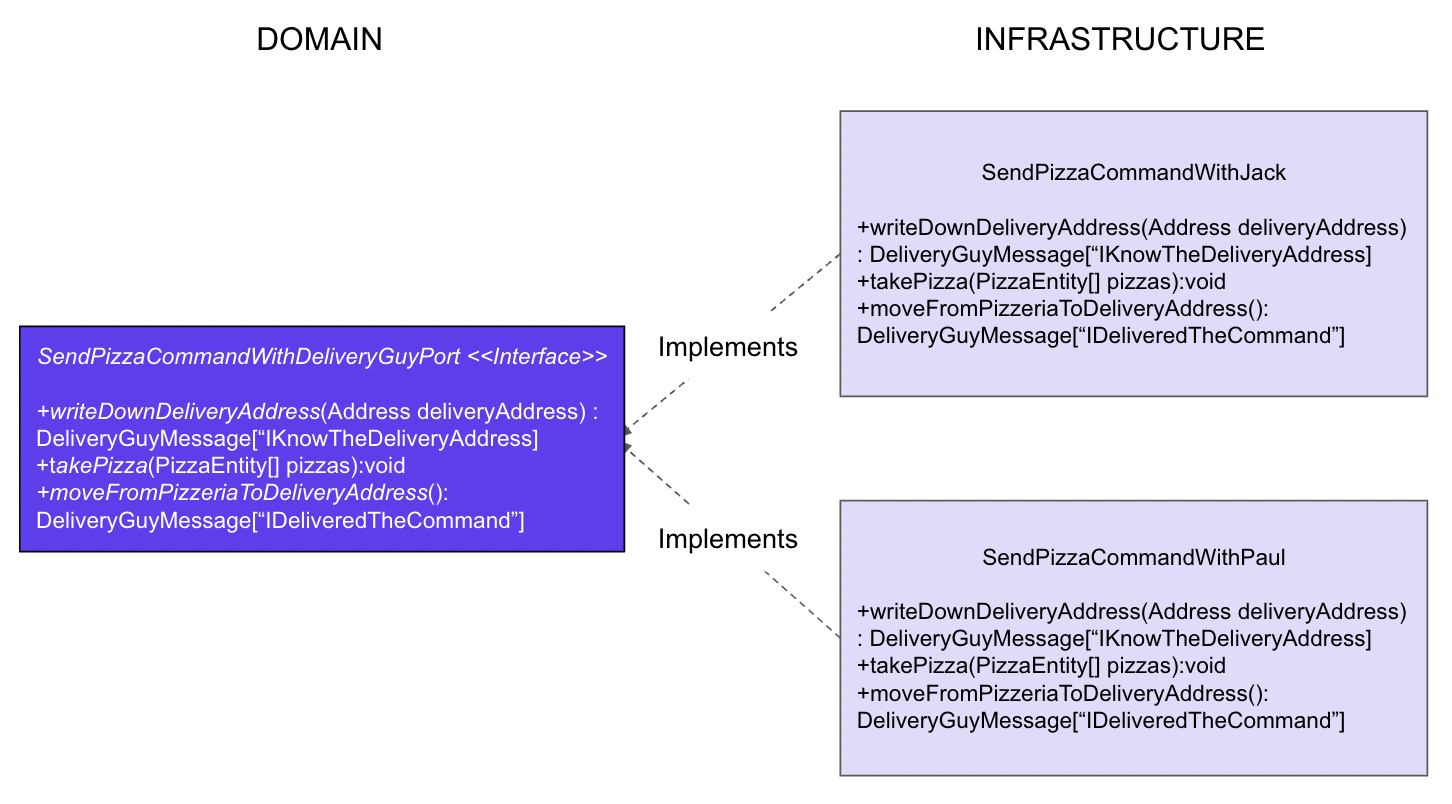
Example of a port and two potentials adapters for pizza command delivery
Warning: you must declare which port is linked to which adapter in the module files. Otherwise, you may face errors about dependencies.
Separate commands and queries
In the domain, you will have to separate methods used to get data from methods that allow you to change data. It is a good way to avoid side effects with retrieval and changes of data at the same moment. Commands are the methods that modify data, while queries are those used to get data.
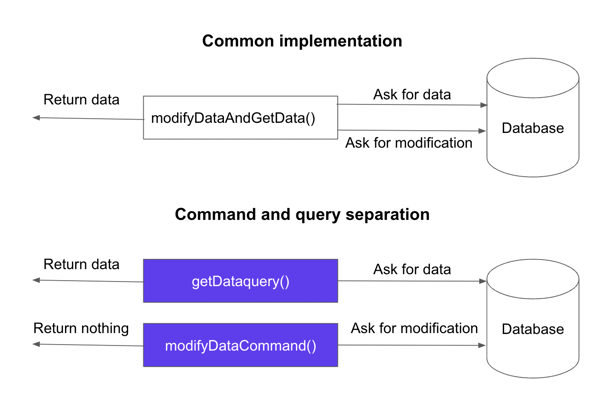
The distinction between command and query segregation and common implementation
In the code, to execute commands and queries you may use a bus. It avoids coupling with a service that contains the implementation. In this case, a command or a query is always a combination of two files. One with the signature and the return type. It is the command or query file. The other contains the logic executed when the method is called via the bus. It is the command handler or query handler file.
I had some misconceptions about how to use commands and queries, here are some big learnings I got:
The importance of entities
Here is an important and not-so-simple aspect of DDH. In common software architectures, a reflex is to create objects corresponding to database elements. In addition, business logic linked to those objects is split into several files.
On the contrary, in DDH, the business logic dictates the objects that should be in the domain. They are the entities. They need to reflect a business reality, not a data persisting model. Furthermore, the aim is to put in the entity all the business logic linked to this entity. This helps us prevent the Anemic Domain Model antipattern.
It is those entities that you will have to manipulate inside the domain to perform actions. Each one must have a unique identifier. To populate them from the persistence system you should use mappers.
Another important role of entities is to protect the domain invariants. Those invariants are business rules considered true everywhere in the domain. (As an example, in our pizza restaurant, the price of a pizza is always strictly positive). Entities must have a constructor that allows the construction of the object only if invariants are respected. During an entity's life cycle, internal methods do not change its state if it goes against the invariants.
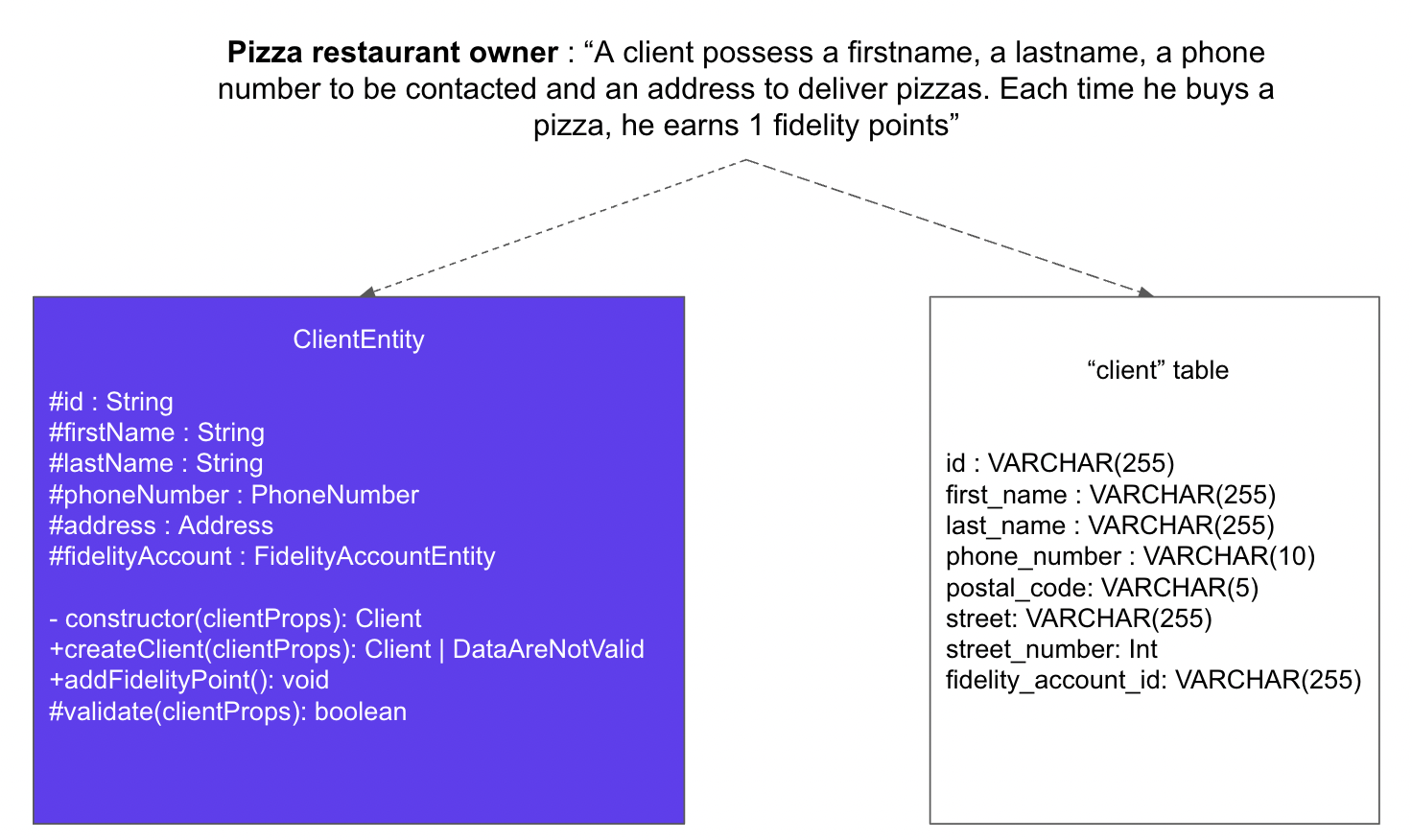
A business case and its implementation
The distinction between entities and aggregates
Now that you’re aware of entities’ power, let’s increase complexity with aggregates.
Aggregates are a gathering of domain objects (entities or value objects) that make sense only together. They offer a second container for business logic inside the domain.
As an example, you may think about a pizza command in a restaurant. The command is always linked to a client and contains one or several pizzas. It also always has a price. Clients and pizzas could be entities, while the price could be a value object in our domain. Actually, those three things are useless alone. What is the interest of the client if he does not consume pizzas? Why cook pizzas if they are not related to a command?
I had some trouble coding my first aggregates, here are some of my learnings:
Never throw domain errors
As you just understand, we must never go against domain invariants. However, attempts to transgress those rules can happen.
Something comforting is that those attempts are predictable because you know your business rules. So you can imagine the way clients may try to bypass them. It is therefore possible to create domain errors that are custom error classes with specific error codes. Each code is associated with a potential error linked to a business rule.
With this approach, three main advantages appear:

As said before, exceptions should be kept only for unpredictable errors. And that is only those exceptions that we want in our error logs to be able to react quickly. Domain errors can be in the logs, but as info or warnings (to keep a track of them). The sooner you implement this, the faster you get useful and clear logs 😏
Add event management
Now that we spoke about errors, let’s think about when everything goes well. You may want to trigger methods in several parts of the domain, even in an external microservice, when some changes are made. How are you supposed to deal with it?
A first solution would be to extract the logic of calls into a specific service. But with this approach, a coupling is created inside the domain, and it is the opposite of DDH goal. A better solution is to build a communication system between our modules or with the outside. It is where event management is interesting.
DDH architecture distinguishes two event types :
In addition to avoiding coupling, events can be used to keep track of executed actions (if their calls are saved in the database for example). It gives a better understanding of state changes in the application.
Your code deserves more DTO (Data Transfer Objects)
At this step, you may be clear with the fact that the domain must not be dependent on something. Therefore, it should not depend on the format of the data sent by the client. Nor the format of data that the client expects to receive.
Here is the aim of Data Transfer Objects (DTOs). They contain sent or received data in a coherent format (with the domain or client needs). Only data formatting logic can be found in those objects, but the format of the data must be insured at this step to ensure that the model will be able to use this data.
On one side, Request DTOs will be instantiated inside the entry point of the domain with client data. Then, only them will be used to populate entities and aggregates. On the other side, Response DTOs will be used to map domain data into the format expected by the client.
A good practice I learnt concerns the response DTOs: always whitelist attributes. It means always enumerate the properties you expect to have in your DTO. Avoid logic that returns all properties of the object except x. With that, even if you change your domain data model and add properties, you will not have data leaks due to a forgotten update of the dto.
Make difference between controller, presenter, and resolver
In order to use all the mechanisms seen previously, we need entry points for the domain. It is the controller/presenter/resolver role. Those elements are in the interface. They are used to receive the requests from outside the module and to execute the appropriate logic inside the domain.
In my last project, we used 3 different entry points:
In an entry point, logic is always the same:
Pro tips: in order to avoid duplication you may prefer to put the data validation inside the command or query handler rather than in the entry point. Otherwise, if you’ve several types of entry points for the same feature, the logic will be in them all.
There is no real theory about how many entry points to have. The only thing is that it is recommended to have one entry point per use case. For our example with the pizza restaurant, we would have entry points for orders, entry points to ask for the spicy sauce, entry points which deal with new clients,..
Conclusion
Here we are, after this walk in the park together. You may have expected other information into those 9 points, but I had to make choices. Nevertheless, I hope that this article will allow you to face your project with more knowledge than 10 minutes ago. To sum up all those concepts, here is the journey of a request to get client information from its id
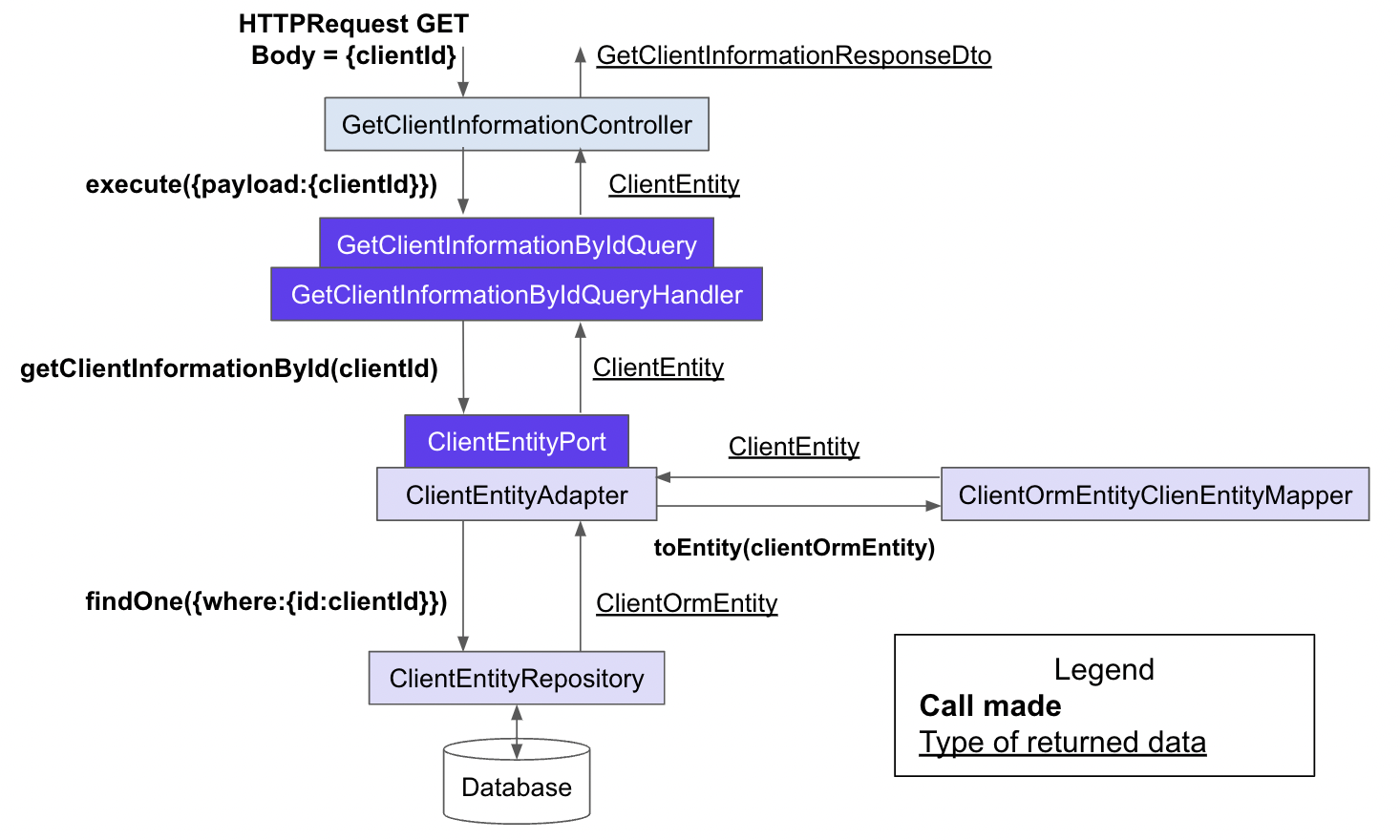
How a request for client information is processed
A last point to remember: DDH architecture is really complex. Facing a lot of uncertainties at the beginning (even months after) is normal. So hang in there, be curious and soon DDH will have a snowball's chance in hell against you.
Sources:
https://github.com/Sairyss/domain-driven-hexagon
https://blog.octo.com/hexagonal-architecture-three-principles-and-an-implementation-example/
https://blog.octo.com/cqrs-larchitecture-aux-deux-visages-partie-1/
https://vaadin.com/blog/ddd-part-3-domain-driven-design-and-the-hexagonal-architecture
Github repository with implementation examples:
https://github.com/Vincent-0708/DDH_ARTICLE
